Privacy on the Internet
by Leo Vegoda

Engineers built the internet with several assumptions front and center. Perhaps first among them was the belief users in this primarily academic environment could be trusted. “Trusted” involves privacy and security, especially. But the internet has escaped academia and is now a dominant form of communication for well over half the world. The trusted community of academic users is now a very small portion of the whole audience.
Plus, commerce has found its way into virtually every corner of the internet. Advertising revenue has almost completed a transition away from print and broadcast media. And automation means that advertisers can know more about internet users than a newspaper publisher ever could.
Advertising buyers no longer have to ‘spray and pray.’ They can target their campaigns with reasonable assurance that they are reaching the people they want to influence. The commercial marketing industry isn’t alone in making use of these new capabilities. Politicians and governments use tracking technology to observe and engage with individuals or small groups around the world.
The identification of individual users and their interests is based on users’ behavior online. Where one browses, purchases, clicks, etc. is often recorded by interested groups. Aggregated, then shared, this information can identify interests of all kinds on a very granular level. Who you are and what you care about can be deduced from what you do online. But behavior tracking isn’t the only form of involuntary characterization by outside parties. We announce who we are and what we (probably) care about in many ways.
Very Broad Terms
Privacy is the condition of being apart from intrusion or observation, physically, emotionally, and/or intellectually. It primarily applies to individuals but can refer to a group separated from others in one way or another. Privacy can be selective in the sense that some information about you can be private and some public. So, it isn’t a condition of absolute invisibility or isolation. And doesn’t always relate to a person. For instance, a particular message can be “private” in the sense that it is conveyed selectively and in such a way that uninvited observers are excluded from access.
Anonymity is closely related but different. It relates to anything that is not ascribed to or explicitly connected with an individual person or group. Extremely public information that is not attributed to an individual is anonymous. Curiously, the word applies to both the statement and the person uttering it. Both are anonymous in the sense that they are not connected to one another.
Security relates to and describes the protections and guarantees associated with providing privacy. A thing is securely private if it is certainly so by means of a reliable system. Normally, security measures are processes developed to provide privacy in some predictable and consistent manner.
The above should make one thing clear: nothing is absolutely private that exists in any public forum. (If you think it, then immediately forget the thought, it was private. Everything else has the chance of worming its way to becoming public.) No system of isolation can be certain to convey content, especially on the internet, such that it can only be retrieved by a single designated recipient. Security systems now in place expand the likelihood of privacy and make intrusion much, much more difficult. Some systems – though usually very cumbersome – are extremely secure. But none is perfect and those that function conveniently are limited to being “very secure” so as not to become grotesquely inconvenient.
Why Care?
On a fairly broad level, privacy and – by extension – anonymity are rights. The Supreme Court has ruled the First Amendment guarantees the right to anonymous speech. The reasoning behind this position is that anonymity “shields” the speaker from “intolerant society.”
Austrian privacy campaigner Max Schrems runs a nonprofit organization to advance privacy. It’s called NOYB, for ‘None of Your Business’. The organization lobbies for the right to be unobserved. That doesn’t mean completely anonymous or isolated. Rather, it means one can become less observed if one chooses to be. NYOB argues for the right to be more invisible, in essence to have technology serve people, in the way they wish, instead of the reverse.
Why Are You Tracked?
Andrew Lewis told us in 2010 that “if you are not paying for it, you’re not the customer; you’re the product being sold.” The underlying truth of this business relationship is simple: most content is paid for by someone, somehow. If one values the thing they watch, read, or listen to they may choose to pay for it directly. Streaming video and audio, and some news sites with pay gates (The New York Times and Apple Music) are good examples. Other means of payment to content providers is the money paid by advertisers to address an audience. When the prior behavior of that audience can be well-known and the future actions tracked, advertisers profit and so pay more for the advertising in question.
In previous generations, advertising was targeted based on the medium. Comic books displayed a different kind of advertising as distinguished from quality newspapers. Special-interest magazines were invented to identify a particular audience whose fandom could be assumed and so their value to advertisers known. But the world has changed, and we get targeted advertising on our devices now. These very specific ads may show up on a generic medium. One may get motorcycle garb advertising on The New York Times, for instance.
Plus, location matters. For instance, a local retailer wants to show online ads only in the vicinity of their store. Buyers can target advertising to a radius as tight as 1km, or based on a jurisdiction, like county, or country. Advertisers refer to this as geo-fenced advertising.
But some people are targets for tracking because of who they are or what they do. Examples include investigative journalists, political campaigners, aristocrats, and the ultra-rich. People want to track them to find out what they are investigating, who they meet with, and where they’ll go next.
Tracking: Individuals vs. Devices
An individual may use a phone, a tablet, a laptop, and a games console. Normally, devices are used by only one user. So, device tracking often exposes the (primary) user to characterization. That is, specific targeting by a consumer profile.
What’s more, they might also be interested in how a device moves among networks. Did a device start the day in a residential neighborhood and then move to a coffee shop, an office, a restaurant, an airport, and finish at a hotel? If it did, companies might want to send specific types of advertising to the main user of that device. After all, even though the device is a gaming machine, its behavior is typical of an adult vis a vis its locations. Advertisers are likely to interpret its movement and target offers accordingly to its traveling owner.
Privacy Measures
IPv4 and NAT
Since the exhaustion of the IPv4 address supply, these addresses have become quite valuable. So, methods have developed to avoid their inefficient use. One way to conserve them is to use a Network Address Translator (NAT) at the edge of a network. It lets the internal network use private addresses, which only have to be locally unique. Which is to say, the same private addresses can be used in multiple networks because they are not used as device locators outside the walls of the closed-wall network on which they work. The NAT substitutes one or more globally unique addresses when exchanging data with other networks and then communicates within the private network using these private IPs.
A side effect of NAT is that it blends the traffic generated by multiple people and devices. For instance, the public WiFi at a café might have a single address and be used by dozens of people every day. Of course, that doesn’t mean that users can’t be tracked when they login to services. But it does mean anonymous use of websites is less likely to be linked to a specific individual.
IPv6 and Randomizing Host Addresses
The IPv6 address format (and so its total population) is so much larger than IPv4 that most people struggle to understand the enormity, not to mention the formatting of these numbers. This address abundance means NAT is not needed to combat scarcity in an IPv6 environment and every device can always have at least one unique IPv6 address.
IPv6 addresses have two parts. The first identifies the network and the second identifies the host, a technical term for the individual device to which it is attached. Originally, hosts would use their unique MAC address – the number assigned to a network card in a device/host – as the host part of their IPv6 address.
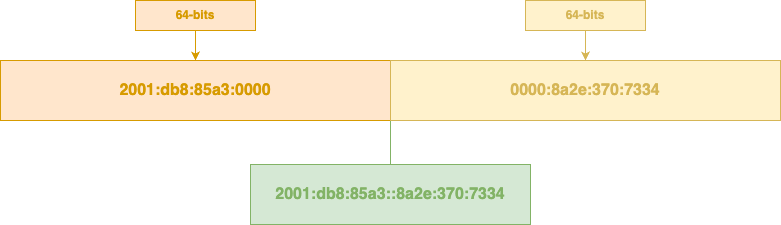
Orange shows the network portion of the address, yellow shows the host portion. Green shows the full address.
This was a simple way of automatically configuring an IPv6 address on a device. The host simply needed to find out the number used for the network and it knew its own IP address. But MAC addresses won’t change on most devices. They are specific to the machine. That means every IPv6 address is automatically linked back to a device and can be tracked over time and as it changes networks.
The 2001 revision of IPv6 framed the problem in the context of a “road warrior” who was tracked as they moved from home to airport, hotel, and so on. 20 years later, the specific use case was dropped because all internet users are now routinely tracked. And the solution, which all major operating systems have deployed, is to generate a random host address and change it regularly.
This means the host portion of the IPv6 address is likely to be both very large and changing. So, a user cannot be identified by a stable device-specific number. The new (temporary) identifier for the host has an even probability of having any value between 0000:0000:0000:0000 and ffff:ffff:ffff:ffff. This is an astronomically large range. It is impractical to draw an association between two different host addresses over time without some other reason. That other reason could be specific user behavior, a web cookie, or web browser fingerprinting.
As with NAT, this approach just blurs users’ identities. A sophisticated analysis by a well-resourced adversary is unlikely to be stopped by address randomization.
DNS: Query Minimization, DoH, and DoT
DNS, the internet’s naming system, was developed in the early 1980s and refined later that decade. Computing was expensive and the early internet was small, so trust was high. No-one cared that every DNS query was sent across the internet in plain text, available for anyone on the path to read. Large scale data capture and analysis was expensive and there was no commercial or intelligence interest in that work anyway.
The web wasn’t developed until 1991 and commercial websites took time to arrive. Amazon launched in 1994, a decade after DNS was first documented.
The Snowden revelations changed the priorities of the engineers. Suddenly, they realized that anything that wasn’t encrypted not only could but would be stored, read, and analyzed. They committed to improve the “privacy properties of IETF protocols” when they met in July 2013.
The first objective was to ensure that deployments “made better use of the security and privacy mechanisms that already existed.” They then discussed what to do next and in 2014 agreed that “pervasive monitoring is a technical attack that should be mitigated in the design of IETF protocols, where possible.” It has been referenced by about 70 protocol documents since then.
Of course, engineers had been working with cryptographic technologies before this. One was DNSSEC. They had focused on the utility of cryptographic signatures to show that DNS answers had not been tampered with by a third-party. They hadn’t worried about making the DNS queries and answers private. Why do you care if someone can see your DNS queries and answers? Because they can be used to describe you. They can tell the operators of the resolver, and anyone else who’s able to watch, where you work, your hobbies, marital status, political interest, sexual preferences and more.
Some people won’t care. Others might have a preference for privacy where it is possible. But some people need as much privacy as possible to aid their professional or personal security. After all, once someone has identified a target, they can use that knowledge to take action. That’s why political activists, some government workers, and the ultra-rich often need additional security.
For instance, a democracy activist in a totalitarian state might need privacy to protect what freedom they have.
Two approaches for improving the privacy of DNS queries are DNS-over-HTTPS, known as DoH, and DNS-over-TLS, known as DoT. They do the same thing in slightly different ways. They create an encrypted tunnel for transporting the initial DNS query and the final answer to a local resolver when the device does not already have a cached answer.
HTTP is the protocol used for web data. Everything from the most basic web page, to streaming media and games are transmitted using HTTP. TLS is Transport Layer Security, the cryptographic protocol used for network security. HTTPS uses TLS to provide security, so they have the same security properties.
More than 90 percent of DNS queries are answered using answers already in a device’s cache, or in the local resolver’s. About 10 percent of DNS queries must be researched to get an answer. If these queries can be linked to you then they can describe you by showing where you work, bank, your political and religious beliefs.
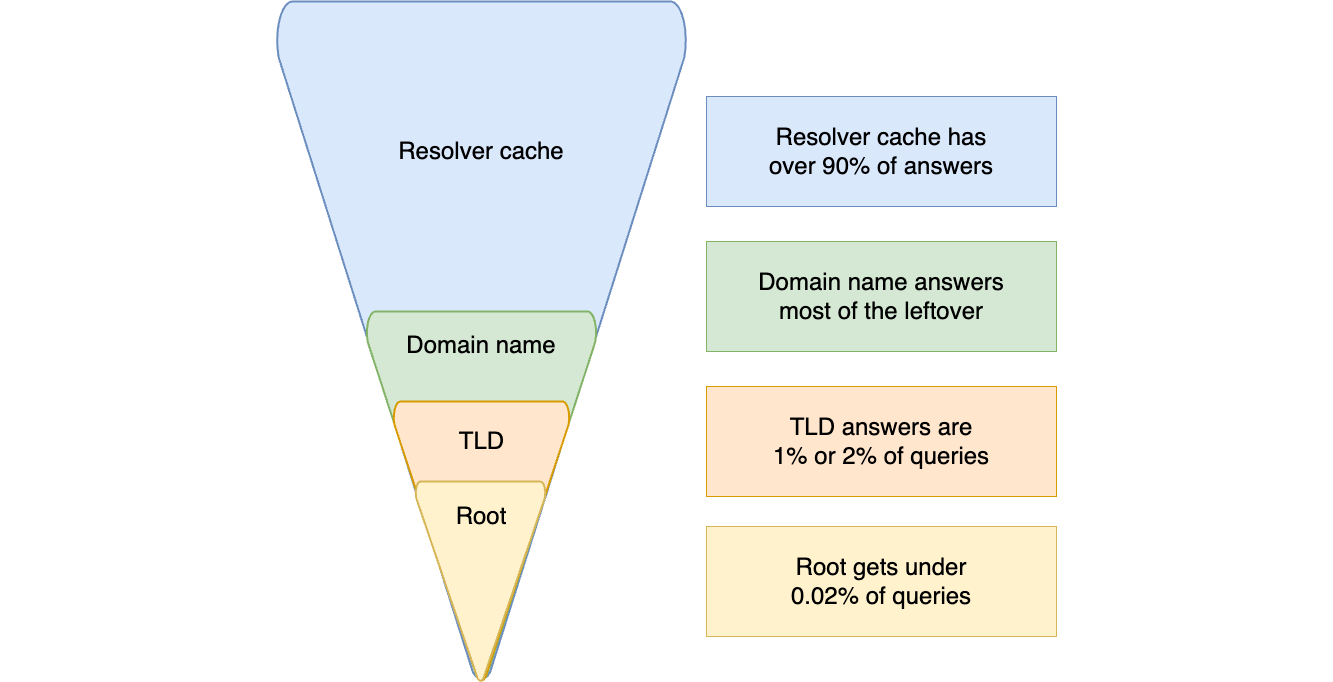
Local resolvers answer almost all queries. About 10% require research. About 1 in 10,000 queries goes all the way to the root of the DNS. Diagram based on RSSAC research.
People whose personal security requires additional privacy might value hiding their DNS queries inside encrypted tunnels. They can still use the local network to access the internet. But the network doesn’t see the names of the websites they visit.
But some security experts are worried that encrypting DNS will hide a lot of information they have relied on for legitimate security analysis. ISPs and others often sell DNS filtering products and they rely on DNS traffic analysis to help them build filters suitable for home and enterprise users. As ever, there is a tension between protecting users through better privacy and making them vulnerable by making it harder to observe malicious behavior.
Your device’s DNS conversation with the resolver can now be encrypted. But the resolver’s research for the 10 percent of answers it does not already have answers for is not encrypted. The query it sends to an authoritative server and the answer it gets are both plain text, so anyone along the path can see that conversation.
This is where DNS Query Name Minimisation comes into play. And it does what the name suggests. Instead of sending a query for the whole DNS name it needs an answer for, it just asks about a part of it. This change in behavior is based on the principle that “the less data you send out, the fewer privacy problems you have.”
This is a change in behavior and not the protocol. The tradition was to always send the whole name being queried but it is not necessary. Users with elevated security requirements can benefit from small changes like this. And commercial organizations can benefit, too.
Some organizations compile and sell information about their users to internet advertising companies and other organizations who want this data. If a DNS operator can reduce the flow of DNS data available to other organizations, it can increase the value of its own data.
HTTP versus HTTPS
The S stands for “Secure”. The original version of HTTP was designed for a high trust environment and did not encrypt anything. Instead, it was like sending a stream of postcards. Anyone on the network could see who was talking and what they were saying. The key difference between real postcards and web traffic is that web traffic flows. Postcards tend to be occasional and rarely share anything personal. But visiting a website involves asking for a page, getting it back, then clicking on a link and getting that page back and so on.
The web encourages prolonged use and people rely on it for private activities, like banking and shopping. Disclosing usernames and passwords over the internet is dangerous, so HTTPS was rolled out for sessions that need to be secured in the late 1990s.
Apple and Google encouraged apps and websites to default to HTTPS by the end of 2016. While the network can see that you connect to an IP address that hosts a specific website, they can’t know which website if that address hosts many sites. That’s why Content Data Networks (CDNs), like Cloudflare, deployed ECH. This is a way of stopping anyone apart from you, the website owner, and the CDN operator from knowing which site you visited.
So, anyone who wants to track users’ web habits will need to do something extra.
Ads, Cookies, and Trackers
But companies and others want to know which websites you visit. And they do their best to follow users around the web.
Advertisers want to know who you are and what you are interested in so they can serve you advertising that will encourage you to take action. They do this with web cookies and web trackers. Cookies are bits of data offered to your web browser by a website. Your browser stores the cookie and then tells that web server, or another, its value when asked.
Authentication cookies are the type users find useful. You login to a website at home, then you go into the office. The cookie in your web browser identifies you, so you can continue your session.
Tracking cookies are the type that report on your browsing history. Advertising and analytics companies use these to profile users and target them with personalized advertising. Countries and states around the world have enacted laws to regulate cookies. Some require users to be given the chance to opt-in (accept cookies on their device), others require an option to opt out.
This is why many websites now present cookie permissions dialog when you first visit.
Example of a cookie permissions dialog seen in a US state with a data privacy law
Wherever you are, all popular web browsers let users clear out cookies and cached files.
Chrome’s ‘Clear Browsing Data’ control
Many people dislike being tracked, and advertisers are among them. Two thirds of people working in advertising use an ad blocker in contrast to just 52 percent of Americans, according to privacy company, Ghostery. Not loading ads and trackers can speed up browsing. This is important when using mobile data. But many people are worried about trackers recording their visits to pages on healthcare or political websites. And people working in advertising distrust the companies gathering this data more than anyone else.
Google’s Chrome and other web browsers support an Application Programming Interface (API) called Manifest. This is the protocol used by small programs that extend the capabilities of the browser. The Manifest API lets them block web advertising.
But Google will replace support for Manifest v2 with v3. This could make it harder to block trackers and ads. Google claims that the change will improve performance by reducing the resource required by extensions. But it comes at the expense of an arbitrary limit on the number of rules adblockers can include. Google’s limit is 30,000 rules but popular adblockers often have 10 times that.
Rival browser, Firefox, will support v3 while retaining support for v2. Ad blocking performance might soon vary between browsers.
VPNs and iCloud Private Relay and TOR
Virtual Private Networks (VPNs) create an encrypted tunnel between devices on one network and devices on another network. Corporate VPNs are used to authenticate users accessing restricted services. For instance, an employee might have to login to a VPN to use internal services when not in the office.
Privacy a key feature of commercial VPNs. Their privacy offer is achieved by blending traffic, like a NAT, and operating their own DNS resolvers. It’s not always possible to know if VPNs truly offer privacy. Some people worry that VPNs could be operated by those who want to gather traffic data.
VPN operators can do two things to demonstrate that they can be trusted. One is to commission an audit and publish the full report. The other is to show they don’t have any user data available when police or the courts demand access to logs. For instance, Mullvad VPN was visited by police but couldn’t help them as it doesn’t log customer data.
Apple’s iCloud Private Relay offers the privacy features of VPNs by hiding your DNS requests and IP address. Even Apple does not have access to the user data. It works in a similar way to Tor, The Onion Router, which was developed by the US Navy.

How Tor works, published the EFF under a CC BY 3.0 license
The key differences are that Apple’s service requires Apple hardware and a subscription. Tor, in contrast, can be used by anyone but is slow as it relies on donated resources. This also reduces its attraction to some criminals. Part of the TOR philosophy is to decentralize operations, which the project claims “keeps Tor users safe.”
Personal Choices
Everyone has their own preferences and risk profile. Many people do not care that advertisers track what they do on the internet. But political activists, journalists, politicians and others might need to be more careful.
Most users won’t have control over whether they use IPv4 or IPv6. That means they probably cannot control if their traffic is blended through a NAT, or their device regularly changes its IPv6 addresses. But users can choose to use HTTPS over HTTP in most cases. And most browsers can be configured to let the user select a DoH resolver. Similarly, users can decide if they need to spend money on a VPN or use a privacy service like iCloud Private Relay or Tor. They can also check the privacy practices and audit reports of the different DNS and VPN providers.
Of course, anyone who can monitor traffic going over the network can see that users establish and send traffic through encrypted tunnels. So, very high risk individuals need to think very carefully about operational security as well as technology choices.